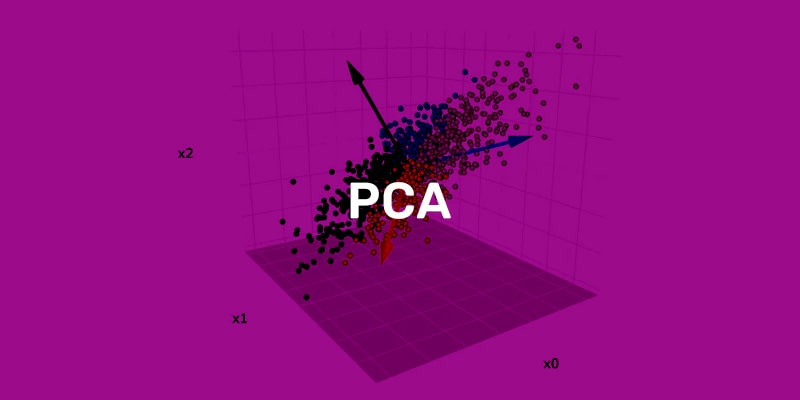
تجزیه و تحلیل اجزای اصلی Principal Component Analysis (PCA) یک تکنیک محبوب در یادگیری ماشین است که برای کاهش ابعاد استفاده می شود.
تجزیه و تحلیل اجزای اصلی (PCA) در یادگیری ماشین
این یک روش آماری است که مجموعه ای از متغیرهای همبسته را به مجموعه جدیدی از متغیرهای غیر همبسته به نام اجزای اصلی تبدیل می کند.
این اجزای اصلی حداکثر مقدار اطلاعات را از داده های اصلی جمع آوری می کنند در حالی که از دست دادن اطلاعات را به حداقل می رسانند.
به زبان ساده، PCA به ساده سازی داده های پیچیده با کاهش تعداد متغیرها بدون از دست دادن اطلاعات زیادی کمک می کند.
این به ویژه در هنگام برخورد با داده های با ابعاد بالا، که در آن تعداد متغیرها زیاد است و می تواند منجر به ناکارآمدی محاسباتی شود، مفید است.
ایده اصلی پشت PCA یافتن یک سیستم مختصات جدید است که در آن داده ها بیشترین پخش را داشته باشند.
این کار با یافتن جهت ها یا محورهایی انجام می شود که داده ها در امتداد آنها بیشترین تغییر را دارند.
به این جهت ها اجزای اصلی می گویند.
مؤلفه اصلی اول حداکثر مقدار تغییر در داده ها را ثبت می کند، مؤلفه اصلی دوم بیشترین مقدار تغییرات را دریافت می کند و غیره.
برای درک نحوه عملکرد PCA، اجازه دهید یک مثال را در نظر بگیریم.
فرض کنید یک مجموعه داده با دو متغیر قد و وزن برای گروهی از افراد داریم.
ما میتوانیم این دادهها را در نمودار پراکنده، با ارتفاع در محور x و وزن در محور y رسم کنیم.
نمودار پراکندگی نشان می دهد که چگونه نقاط داده در این فضای دو بعدی توزیع شده اند.
حال تصور کنید که می خواهیم ابعاد این داده ها را از دو به یک کاهش دهیم.
ما میخواهیم یک خط واحد به نام مؤلفه اصلی پیدا کنیم که دادهها در آن بیشترین پخش را داشته باشند.
این خط حداکثر مقدار اطلاعات را از داده های اصلی دریافت می کند.
برای یافتن این خط، PCA ماتریس کوواریانس داده ها را محاسبه می کند.
ماتریس کوواریانس به ما می گوید که چگونه متغیرهای موجود در داده ها با یکدیگر مرتبط هستند.
اطلاعاتی در مورد جهت و قدرت رابطه بین متغیرها به ما می دهد.
هنگامی که ماتریس کوواریانس را داشته باشیم، PCA بردارهای ویژه و مقادیر ویژه این ماتریس را پیدا می کند.
بردارهای ویژه نشان دهنده جهت هایی هستند که داده ها در امتداد آنها بیشترین تغییر را دارند و مقادیر ویژه نشان دهنده میزان تغییرات در این جهات هستند.
بردار ویژه با بالاترین مقدار ویژه با اولین جزء اصلی مطابقت دارد.
این بردار ویژه جهتی را به ما می دهد که داده ها در آن بیشترین پخش را دارند.
ما میتوانیم دادهها را روی این بردار ویژه طرح کنیم تا نمایش تک بعدی دادهها را به دست آوریم.
با استفاده از PCA، میتوانیم ابعاد دادهها را از دو به یک کاهش دهیم، در حالی که همچنان بیشتر اطلاعات را ضبط میکنیم.
این می تواند در کاربردهای مختلف مانند فشرده سازی تصویر مفید باشد، جایی که کاهش ابعاد داده ها می تواند منجر به صرفه جویی قابل توجهی در ذخیره سازی و محاسباتی شود.
در نتیجه، PCA یک تکنیک قدرتمند در یادگیری ماشینی است که به کاهش ابعاد کمک می کند.
جهت هایی را پیدا می کند که داده ها در امتداد آنها بیشترین تغییر را دارند و داده ها را بر روی این جهت ها به نمایش می گذارد تا نمایش جدیدی به دست آورد.
با کاهش ابعاد داده ها، PCA مجموعه داده های پیچیده را ساده می کند و امکان محاسبات کارآمدتر را فراهم می کند.
درک ریاضیات پشت PCA در یادگیری ماشین
یادگیری ماشین PCA چیست؟ اگر در دنیای یادگیری ماشینی تازه کار هستید، ممکن است با اصطلاح PCA برخورد کرده باشید.
اما دقیقا به چه معناست؟ PCA مخفف عبارت Principal Component Analysis است و یک تکنیک ریاضی است که در یادگیری ماشین برای کاهش ابعاد یک مجموعه داده استفاده می شود.
به عبارت ساده تر، به ما کمک می کند تا داده های پیچیده را با تبدیل آنها به فضایی با ابعاد پایین تر درک و تجسم کنیم.
برای درک PCA، باید به ریاضیات پشت آن بپردازیم.
نگران نباشید، ما خیلی فنی نمی شویم! PCA در هسته خود به دنبال یافتن الگوها و روابط در داده ها است.
این کار را با شناسایی جهتها یا اجزای اصلی انجام میدهد که دادهها در امتداد آنها بیشترین تفاوت را دارند.
این اجزای اصلی اساساً متغیرهای جدیدی هستند که مهم ترین اطلاعات را از مجموعه داده اصلی دریافت می کنند.
بنابراین چگونه PCA به این امر دست می یابد؟ با محاسبه ماتریس کوواریانس مجموعه داده شروع می شود.
ماتریس کوواریانس به ما می گوید که چگونه هر متغیر در مجموعه داده با هر متغیر دیگری مرتبط است.
با تجزیه و تحلیل این ماتریس، PCA جهت هایی را تعیین می کند که داده ها در امتداد آنها بیشترین تغییر را دارند.
این جهت ها اجزای اصلی هستند.
هنگامی که اجزای اصلی شناسایی شدند، PCA داده های اصلی را روی این مؤلفه ها پروژه می دهد.
این طرح به ما اجازه می دهد تا داده ها را در فضایی با ابعاد کمتر تجسم کنیم.
اولین جزء اصلی بیشترین تنوع را در داده ها ثبت می کند و به دنبال آن دومی و غیره.
با انتخاب نگه داشتن تنها زیر مجموعه ای از اجزای اصلی، می توانیم ابعاد مجموعه داده را کاهش دهیم.

اما چرا می خواهیم ابعاد داده های خود را کاهش دهیم؟ خوب، تجزیه و تحلیل و تجسم داده های با ابعاد بالا می تواند دشوار باشد.
با کاهش تعداد متغیرها، میتوانیم دادهها را سادهسازی کنیم و آنها را قابل مدیریتتر کنیم.
این می تواند به ویژه هنگام کار با مجموعه داده های بزرگ یا هنگام تلاش برای شناسایی مهم ترین ویژگی های یک مجموعه داده مفید باشد.
PCA همچنین کاربردهای دیگری در یادگیری ماشین دارد.
به عنوان مثال، می توان از آن برای پیش پردازش داده ها استفاده کرد، جایی که به حذف نویز و اطلاعات اضافی از داده ها کمک می کند.
همچنین می تواند برای استخراج ویژگی استفاده شود، جایی که به شناسایی آموزنده ترین ویژگی ها در یک مجموعه داده کمک می کند.
با کاهش ابعاد داده ها، PCA می تواند عملکرد الگوریتم های یادگیری ماشین را بهبود بخشد و آنها را کارآمدتر کند.
در نتیجه، PCA یک تکنیک ریاضی قدرتمند است که در یادگیری ماشین برای کاهش ابعاد یک مجموعه داده استفاده میشود.
PCA با شناسایی جهت هایی که داده ها بیشترین تغییر را دارند، به ما امکان می دهد داده های پیچیده را در فضایی با ابعاد پایین تر تجسم و تجزیه و تحلیل کنیم.
کاربردهای مختلفی در یادگیری ماشین دارد، از پیش پردازش داده تا استخراج ویژگی.
بنابراین دفعه بعد که با اصطلاح PCA برخورد کردید، متوجه خواهید شد که همه چیز در مورد درک ریاضیات پشت کاهش پیچیدگی داده ها است.
کاربردهای PCA در یادگیری ماشین
اکنون که درک اساسی از یادگیری ماشینی PCA داریم، اجازه دهید برخی از کاربردهای آن را در این زمینه بررسی کنیم.
PCA یا تجزیه و تحلیل اجزای اصلی، یک تکنیک قدرتمند است که می تواند برای کاهش ابعاد یک مجموعه داده و در عین حال حفظ مهم ترین ویژگی های آن استفاده شود.
این امر آن را به ویژه در یادگیری ماشینی مفید می کند، جایی که پرداختن به داده های با ابعاد بالا می تواند چالش برانگیز باشد.
یکی از کاربردهای رایج PCA در یادگیری ماشین، در تشخیص تصویر است.
تصاویر معمولاً به صورت آرایههایی با ابعاد بالا از مقادیر پیکسل نشان داده میشوند که پردازش مستقیم آنها را دشوار میکند.
با اعمال PCA روی این تصاویر، می توانیم ابعاد آنها را کاهش دهیم و در عین حال مهم ترین اطلاعات را حفظ کنیم.
این نه تنها کار با تصاویر را آسانتر میکند، بلکه به بهبود دقت مدلهای یادگیری ماشینی آموزشدیده بر روی آنها نیز کمک میکند.
حوزه دیگری که در آن PCA به طور گسترده استفاده می شود، در تشخیص ناهنجاری است.
ناهنجاری ها یا نقاط پرت، نقاط داده ای هستند که به طور قابل توجهی از هنجار منحرف می شوند.
تشخیص این ناهنجاریها در حوزههای مختلف، مانند کشف تقلب در امور مالی یا شناسایی تجهیزات معیوب در تولید، حیاتی است.
PCA می تواند برای شناسایی اجزای اصلی یک مجموعه داده و سپس تعیین میزان انحراف هر نقطه داده از این اجزا استفاده شود.
این به ما امکان می دهد تا ناهنجاری های احتمالی را علامت گذاری کنیم و اقدامات مناسب را انجام دهیم.
کاهش ابعاد یکی دیگر از کاربردهای کلیدی PCA در یادگیری ماشینی است.
همانطور که قبلا ذکر شد، کار با داده های با ابعاد بالا به دلیل نفرین ابعاد می تواند چالش برانگیز باشد.
با استفاده از PCA، میتوانیم تعداد ویژگیهای یک مجموعه داده را کاهش دهیم و در عین حال بیشتر اطلاعات را حفظ کنیم.
این نه تنها داده ها را ساده می کند، بلکه به بهبود عملکرد الگوریتم های یادگیری ماشین نیز کمک می کند.
با ابعاد کمتر، مدلها قابل تفسیرتر میشوند و کمتر مستعد بیش از حد برازش هستند.
فیلتر مشارکتی، تکنیکی که معمولا در سیستم های توصیه استفاده می شود، از PCA نیز سود می برد.
در فیلترینگ مشارکتی، هدف پیشبینی اولویتهای کاربر بر اساس ترجیحات کاربران مشابه است.
با این حال، هنگامی که با تعداد زیادی از کاربران و آیتم ها سروکار دارید، داده ها می توانند به سرعت ابعاد بالایی پیدا کنند.
PCA را می توان برای کاهش ابعاد این داده ها استفاده کرد و یافتن شباهت ها بین کاربران و بهبود دقت توصیه ها را آسان تر می کند.
در نهایت، PCA را می توان در وظایف پردازش زبان طبیعی (NLP) مانند طبقه بندی متن یا تجزیه و تحلیل احساسات به کار برد.
دادههای متنی معمولاً بهعنوان بردارهایی با ابعاد بالا نشان داده میشوند، جایی که هر بعد مربوط به یک کلمه یا عبارت منحصربهفرد است.
با استفاده از PCA می توانیم ابعاد این بردارها را کاهش دهیم و در عین حال مهم ترین اطلاعات را حفظ کنیم.
این نه تنها پردازش داده های متنی را سرعت می بخشد، بلکه به بهبود عملکرد مدل های یادگیری ماشین آموزش داده شده بر روی آن کمک می کند.
در نتیجه، یادگیری ماشینی PCA طیف گسترده ای از کاربردها در حوزه های مختلف دارد.
از تشخیص تصویر گرفته تا تشخیص ناهنجاری، کاهش ابعاد تا فیلتر مشترک، و حتی در وظایف NLP، PCA یک ابزار ارزشمند است.
با کاهش ابعاد مجموعه دادههای با ابعاد بالا، PCA به سادهسازی دادهها، بهبود عملکرد مدل و تفسیرپذیرتر کردن مدلها کمک میکند.
با ادامه پیشرفت یادگیری ماشین، PCA احتمالاً یک تکنیک اساسی در این زمینه باقی خواهد ماند.
مزایا و محدودیت های PCA در یادگیری ماشین
تجزیه و تحلیل مؤلفه اصلی (PCA) یک تکنیک پرکاربرد در یادگیری ماشینی است که به کاهش ابعاد یک مجموعه داده کمک می کند.
با تبدیل داده ها به فضایی با ابعاد پایین تر، PCA امکان تجسم و تجزیه و تحلیل آسان تر را فراهم می کند.
در این مقاله، مزایا و محدودیت های PCA در یادگیری ماشین را بررسی خواهیم کرد.
یکی از مزایای اصلی PCA توانایی آن در ساده سازی مجموعه داده های پیچیده است.
هنگام برخورد با داده های با ابعاد بالا، درک الگوها و روابط زیربنایی می تواند چالش برانگیز باشد.
PCA با شناسایی مؤلفههای اصلی، که جهتهایی در دادهها هستند که بیشترین واریانس را ثبت میکنند، به این موضوع میپردازد.
این مؤلفه ها اساساً متغیرهای جدیدی هستند که ترکیبی خطی از ویژگی های اصلی هستند.
با کاهش ابعاد داده ها، PCA به حذف اطلاعات اضافی و نامربوط کمک می کند.
این نه تنها مجموعه داده را ساده می کند، بلکه کارایی محاسباتی را نیز بهبود می بخشد.
با ابعاد کمتر، الگوریتمهای یادگیری ماشینی میتوانند دادهها را سریعتر پردازش کنند و PCA را به ابزاری ارزشمند برای مجموعههای داده در مقیاس بزرگ تبدیل کنند.
یکی دیگر از مزایای PCA توانایی آن در افزایش قابلیت تفسیر است.
با تجسم داده ها در فضایی با ابعاد پایین تر، شناسایی خوشه ها، نقاط پرت و سایر الگوها آسان تر می شود.
این می تواند به ویژه در تجزیه و تحلیل داده های اکتشافی مفید باشد، جایی که درک ساختار داده ها بسیار مهم است.
PCA راهی برای نمایش داده ها به شیوه ای معنادارتر و قابل درک تر ارائه می دهد.
علاوه بر این، PCA می تواند برای استخراج ویژگی استفاده شود.
در بسیاری از موارد، ویژگی های اصلی ممکن است مستقیماً به کار مورد نظر مربوط نباشد.
با تبدیل داده ها به فضایی با ابعاد کمتر، PCA می تواند مهمترین ویژگی ها را برجسته کند.
این می تواند به ویژه در شرایطی که منابع محاسباتی محدودی وجود دارد یا هنگام برخورد با داده های با ابعاد بالا مفید باشد.
با وجود مزایای آن، PCA محدودیت هایی نیز دارد.
یک محدودیت این است که در داده ها خطی بودن را فرض می کند.
PCA زمانی بهترین کار می کند که رابطه بین متغیرها خطی باشد.
اگر داده ها روابط غیر خطی را نشان دهند، PCA ممکن است ساختار زیربنایی را به درستی ثبت نکند.
در چنین مواردی، تکنیکهای کاهش ابعاد جایگزین، مانند هسته PCA، ممکن است مناسبتر باشند.
یکی دیگر از محدودیت های PCA این است که به نقاط پرت حساس است.
نقاط پرت می توانند به طور قابل توجهی بر اجزای اصلی تأثیر بگذارند و منجر به نمایش تحریف داده ها شوند.
بنابراین، مهم است که قبل از اعمال PCA، داده ها را از قبل پردازش کنید و نقاط پرت را حذف کنید.
علاوه بر این، PCA ممکن است برای مجموعه دادههایی با متغیرهای طبقهبندی یا مقادیر گمشده مناسب نباشد، زیرا به دادههای عددی نیاز دارد.
علاوه بر این، PCA می تواند منجر به از دست دادن قابلیت تفسیر شود.
در حالی که PCA داده ها را ساده می کند، این کار را با ایجاد متغیرهای جدید که ترکیبی خطی از ویژگی های اصلی هستند انجام می دهد.
این متغیرهای جدید ممکن است تفسیر مستقیمی در زمینه مشکل نداشته باشند.
بنابراین، در نظر گرفتن مبادله بین تفسیرپذیری و کاهش ابعاد در هنگام استفاده از PCA مهم است.
در نتیجه، PCA یک تکنیک قدرتمند در یادگیری ماشینی است که چندین مزیت را ارائه می دهد.
این مجموعه داده های پیچیده را ساده می کند، قابلیت تفسیر را افزایش می دهد و می تواند برای استخراج ویژگی استفاده شود.
با این حال، آگاهی از محدودیتهای آن، مانند فرض خطی بودن، حساسیت به موارد پرت و از دست دادن بالقوه قابلیت تفسیر، مهم است.
با درک این مزایا و محدودیتها، متخصصان یادگیری ماشینی میتوانند هنگام اعمال PCA در مجموعه دادههای خود تصمیمات آگاهانه بگیرند.
پیاده سازی PCA در الگوریتم های یادگیری ماشین
تجزیه و تحلیل مؤلفه اصلی (PCA) یک تکنیک پرکاربرد در یادگیری ماشینی است که به کاهش ابعاد یک مجموعه داده کمک می کند.
PCA با تبدیل ویژگی های اصلی به مجموعه جدیدی از متغیرهای نامرتبط به نام مؤلفه های اصلی، پیچیدگی داده ها را ساده می کند و در عین حال بیشتر اطلاعات مهم خود را حفظ می کند.
در این مقاله، چگونگی پیادهسازی PCA را در الگوریتمهای مختلف یادگیری ماشین بررسی خواهیم کرد.
یکی از مزایای اصلی PCA توانایی آن در مدیریت داده های با ابعاد بالا است.
هنگامی که با مجموعه داده هایی که دارای تعداد زیادی ویژگی هستند، کار می کنیم، تجزیه و تحلیل و تجسم داده ها به طور موثر چالش برانگیز می شود.
PCA با شناسایی جهت هایی که داده ها در آنها بیشترین تفاوت را دارند و نمایش داده ها در این جهت ها به این موضوع می پردازد.
این منجر به نمایش داده ها با ابعاد کمتر می شود و کار با آن را آسان تر می کند.
پیاده سازی PCA در الگوریتم های یادگیری ماشینی شامل چند مرحله کلیدی است.
ابتدا، مجموعه داده باید استاندارد شود تا اطمینان حاصل شود که همه ویژگی ها مقیاس یکسانی دارند.
این مهم است زیرا PCA به مقیاس متغیرها حساس است.
با استانداردسازی دادهها، میتوانیم اطمینان حاصل کنیم که هر ویژگی به طور مساوی در تجزیه و تحلیل نقش دارد.
هنگامی که داده ها استاندارد شدند، مرحله بعدی محاسبه ماتریس کوواریانس است.
ماتریس کوواریانس اطلاعاتی در مورد روابط بین ویژگی های مختلف در مجموعه داده ارائه می دهد.
این به شناسایی جهت هایی که داده ها در آنها بیشترین تفاوت را دارند کمک می کند.
سپس بردارهای ویژه و مقادیر ویژه ماتریس کوواریانس محاسبه می شوند.
بردارهای ویژه مؤلفه های اصلی را نشان می دهند، در حالی که مقادیر ویژه میزان واریانس توضیح داده شده توسط هر مؤلفه اصلی را نشان می دهند.
پس از به دست آوردن بردارهای ویژه و مقادیر ویژه، مرحله بعدی انتخاب تعداد اجزای اصلی برای حفظ است.
این تصمیم بسیار مهم است زیرا مقدار اطلاعات حفظ شده از مجموعه داده اصلی را تعیین می کند.
یکی از رویکردهای رایج انتخاب تعداد مؤلفه های اصلی است که درصد معینی از واریانس کل را توضیح می دهد.
برای مثال، اگر بخواهیم 95 درصد واریانس را حفظ کنیم، تعداد مؤلفههای اصلی را انتخاب میکنیم که به طور تجمعی 95 درصد واریانس کل را توضیح میدهند.
هنگامی که تعداد مؤلفه های اصلی مشخص شد، داده ها را می توان با نمایش آن بر روی مؤلفه های اصلی انتخاب شده تبدیل کرد.
این تبدیل منجر به نمایشی با ابعاد پایین تر از داده ها می شود، جایی که هر مشاهده با مقادیر متناظر آن در امتداد اجزای اصلی نمایش داده می شود.
سپس این داده های تبدیل شده می توانند به عنوان ورودی برای الگوریتم های مختلف یادگیری ماشین استفاده شوند.
پیاده سازی PCA در الگوریتم های یادگیری ماشین مزایای متعددی را ارائه می دهد.
در مرحله اول، به کاهش ابعاد داده ها کمک می کند، که می تواند کارایی و عملکرد الگوریتم ها را بهبود بخشد.
PCA با حذف ویژگی های نامربوط یا اضافی، نویز در داده ها را کاهش می دهد و بر مهمترین اطلاعات تمرکز می کند.
این می تواند به دقت بهتر و زمان محاسبات سریعتر منجر شود.
علاوه بر این، PCA همچنین می تواند در تجسم داده های با ابعاد بالا کمک کند.
با کاهش ابعاد، PCA به ما این امکان را میدهد که دادهها را در فضایی با ابعاد پایینتر رسم کنیم و تفسیر و تحلیل آن را آسانتر میکند.
این می تواند به ویژه در تجزیه و تحلیل داده های اکتشافی و وظایف تجسم داده ها مفید باشد.
در نتیجه، PCA یک تکنیک قدرتمند در یادگیری ماشینی است که پیچیدگی داده های با ابعاد بالا را ساده می کند.
با تبدیل ویژگی های اصلی به مجموعه جدیدی از متغیرهای غیر همبسته، PCA ابعاد را کاهش می دهد در حالی که بیشتر اطلاعات مهم را حفظ می کند.
پیادهسازی PCA در الگوریتمهای یادگیری ماشین شامل استانداردسازی دادهها، محاسبه ماتریس کوواریانس، محاسبه بردارهای ویژه و مقادیر ویژه، انتخاب تعداد مؤلفههای اصلی و تبدیل دادهها است.
این تکنیک چندین مزیت از جمله بهبود کارایی، دقت بهتر، زمانهای محاسباتی سریعتر و قابلیتهای بصریسازی دادهها را افزایش میدهد.
منبع » آکادمی اشکان مستوفی




