یادگیری ماشین به بخشی جدایی ناپذیر از زندگی ما تبدیل شده است، از دستیارهای صوتی مانند سیری و الکسا تا شخصی سازی شده توصیه هایی در مورد سیستم عامل های جریان اما آیا تا به حال فکر کرده اید که این مدل های یادگیری ماشینی چگونه کار می کنند؟ یک مفهوم مهم برای درک، واریانس Variance در مدل های یادگیری ماشین است.
واریانس به مقداری اشاره دارد که پیشبینیهای یک مدل یادگیری ماشین برای مجموعههای آموزشی مختلف متفاوت است.
واریانس Variance
به عبارت ساده تر، میزان حساسیت مدل به داده های آموزشی که در معرض آن قرار می گیرد را اندازه گیری می کند.
واریانس Variance بالا به این معنی است که مدل بسیار نزدیک به دادههای آموزشی برازش میکند و در نتیجه عملکرد ضعیفی روی دادههای دیده نشده دارد.
از سوی دیگر، واریانس کم نشان می دهد که مدل به اندازه کافی با داده های آموزشی برازش نمی کند و منجر به عملکرد ضعیف می شود.
برای درک بهتر واریانس، اجازه دهید یک مثال را در نظر بگیریم.
تصور کنید مجموعه داده ای از قیمت مسکن دارید و می خواهید یک مدل یادگیری ماشینی بسازید تا قیمت خانه را بر اساس ویژگی های آن پیش بینی کنید.
مجموعه داده خود را به یک مجموعه آموزشی و یک مجموعه آزمایشی تقسیم می کنید.
شما مدل خود را روی مجموعه آموزشی آموزش می دهید و عملکرد آن را در مجموعه تست ارزیابی می کنید.
اگر مدل شما واریانس بالایی دارد، به این معنی است که داده های آموزشی بیش از حد برازش می کند.
این در حال گرفتن نویز و نوسانات تصادفی در مجموعه آموزشی است که ممکن است در دنیای واقعی وجود نداشته باشد.
در نتیجه، وقتی مدل را روی مجموعه آزمایشی ارزیابی میکنید، عملکرد ضعیفی دارد زیرا نمیتواند به خوبی به دادههای دیده نشده تعمیم دهد.
از طرف دیگر، اگر مدل شما واریانس پایینی داشته باشد، به این معنی است که داده های آموزشی را نادیده گرفته است.
الگوها و روابط زیربنایی در دادهها را نمیگیرد، که منجر به عملکرد ضعیف در مجموعههای آموزشی و آزمایشی میشود.
در این مورد، مدل بسیار ساده است و پیچیدگی لازم برای پیشبینی دقیق را ندارد.
بنابراین، چگونه می توانیم به مسئله واریانس در مدل های یادگیری ماشین رسیدگی کنیم؟ یکی از رویکردهای رایج استفاده از تکنیک های منظم سازی است.
منظمسازی یک عبارت جریمه به تابع هدف مدل اضافه میکند و آن را از برازش بیش از حد دادههای آموزشی منصرف میکند.
این به کاهش واریانس و بهبود توانایی تعمیم مدل کمک می کند.
راه دیگر برای مقابله با واریانس، افزایش اندازه مجموعه آموزشی است.
با قرار دادن مدل در معرض نمونههای متنوعتر، احتمال تطابق بیش از حد دادههای آموزشی کمتر میشود.
این به این دلیل است که مدل یاد می گیرد به جای به خاطر سپردن نمونه های خاص، الگوها و روابط اساسی در داده ها را ثبت کند.
اعتبارسنجی متقاطع نیز یک تکنیک مفید برای ارزیابی و کاهش واریانس است.
اعتبارسنجی متقابل به جای تکیه بر یک تقسیم آزمون قطار، شامل تقسیم داده ها به زیر مجموعه های متعدد و آموزش مدل بر روی ترکیب های مختلف این زیر مجموعه ها است.
این به ارائه تخمین قوی تر از عملکرد مدل کمک می کند و تأثیر هر مجموعه آموزشی خاص را کاهش می دهد.
در نتیجه، واریانس Variance یک مفهوم مهم در مدلهای یادگیری ماشین است.
حساسیت مدل به داده های آموزشی را اندازه گیری می کند و بر توانایی آن در تعمیم به داده های دیده نشده تأثیر می گذارد.
واریانس بالا منجر به برازش بیش از حد می شود، در حالی که واریانس کم منجر به عدم تناسب می شود.
منظمسازی، افزایش اندازه مجموعه آموزشی و اعتبارسنجی متقابل برخی از تکنیکهایی هستند که میتوانند به رفع مشکل واریانس و بهبود عملکرد مدلهای یادگیری ماشین کمک کنند.
با درک و مدیریت واریانس، میتوانیم مدلهای یادگیری ماشینی دقیقتر و مطمئنتری بسازیم که میتوانند پیشبینیهای بهتری در حوزههای مختلف انجام دهند.
تکنیک ها برای کاهش واریانس در الگوریتم های یادگیری ماشین
الگوریتم های یادگیری ماشینی ابزارهای قدرتمندی هستند که می توانند مقادیر زیادی از داده ها را برای پیش بینی و تصمیم گیری تجزیه و تحلیل و تفسیر کنند.
با این حال، یکی از چالش های رایج در یادگیری ماشین، مقابله با واریانس است.
واریانس به حساسیت یک مدل به داده های خاصی که روی آن آموزش داده شده است اشاره دارد.
به عبارت دیگر، یک مدل با واریانس بالا ممکن است بر روی داده های آموزشی عملکرد خوبی داشته باشد اما نتواند به داده های جدید و نادیده تعمیم یابد.
کاهش واریانس در یادگیری ماشین بسیار مهم است زیرا میخواهیم مدلهای ما بتوانند پیشبینیهای دقیقی بر روی دادههای جدید انجام دهند.
خوشبختانه، چندین تکنیک وجود دارد که می تواند به ما در حل این مشکل کمک کند.
یکی از تکنیک های کاهش واریانس منظم سازی نامیده می شود.
منظم سازی شامل اضافه کردن یک عبارت جریمه به تابع ضرر یک مدل است.
این عبارت جریمه مدل را از برازش بیش از حد داده های آموزشی منع می کند و در عوض آن را تشویق می کند تا راه حل کلی تری پیدا کند.
این به جلوگیری از برازش بیش از حد کمک می کند، که یکی از دلایل رایج واریانس بالا است.
منظمسازی را میتوان از طریق تکنیکهایی مانند منظمسازی L1 و L2 به دست آورد که مقادیر مطلق یا مجذور وزنهای مدل را به تابع ضرر اضافه میکنند.
روش دیگری برای کاهش واریانس، اعتبارسنجی متقاطع نام دارد.
اعتبار سنجی متقاطع شامل تقسیم داده ها به زیر مجموعه های متعدد یا فولدها و آموزش مدل بر روی ترکیب های مختلف این تاها است.
با ارزیابی عملکرد مدل در هر چین، میتوانیم تخمین دقیقتری از توانایی تعمیم آن بدست آوریم.
این به کاهش تأثیر هر زیرمجموعه خاصی از داده ها که ممکن است باعث ایجاد واریانس بالا شوند کمک می کند.
روش های گروهی یکی دیگر از تکنیک های موثر برای کاهش واریانس است.
روشهای مجموعه شامل ترکیب پیشبینیهای چند مدل برای ایجاد یک پیشبینی نهایی است.
این را می توان از طریق تکنیک هایی مانند بسته بندی، تقویت یا انباشتن انجام داد.
با ترکیب پیشبینیهای چند مدل، روشهای مجموعه میتوانند به کاهش واریانس پیشبینی نهایی کمک کنند.
دلیل این امر این است که مدل های مختلف ممکن است منابع خطای متفاوتی داشته باشند و با ترکیب آنها می توانیم تأثیر خطاهای هر مدل را کاهش دهیم.
انتخاب ویژگی تکنیک دیگری است که می تواند به کاهش واریانس کمک کند.
انتخاب ویژگی شامل شناسایی و انتخاب مرتبط ترین ویژگی ها از مجموعه داده است.
با حذف ویژگی های نامربوط یا زائد، می توانیم پیچیدگی مدل را کاهش دهیم و توانایی تعمیم آن را بهبود دهیم.
این می تواند با کاهش احتمال تطبیق بیش از حد به ویژگی های پر سر و صدا یا نامربوط به کاهش واریانس کمک کند.
در نهایت، افزایش اندازه مجموعه داده آموزشی نیز می تواند به کاهش واریانس کمک کند.
با داده های بیشتر، مدل شانس بیشتری برای گرفتن الگوها و روابط زیربنایی در داده ها دارد.
این می تواند به کاهش تأثیر هر زیرمجموعه خاصی از داده ها که ممکن است باعث ایجاد واریانس بالا شود کمک کند.
در نتیجه، کاهش واریانس یک جنبه مهم یادگیری ماشین است.
با استفاده از تکنیکهایی مانند منظمسازی، اعتبارسنجی متقابل، روشهای مجموعه، انتخاب ویژگی و افزایش اندازه مجموعه دادههای آموزشی، میتوانیم توانایی تعمیم مدلهای خود را بهبود بخشیم و پیشبینیهای دقیقتری روی دادههای جدید و دیده نشده انجام دهیم.
این تکنیکها ابزارهای ارزشمندی در جعبه ابزار یادگیری ماشین هستند و باید هنگام برخورد با واریانس بالا در الگوریتمهای یادگیری ماشین در نظر گرفته شوند.
تأثیر واریانس عملکرد و تعمیم مدل
یادگیری ماشینی روشی را که ما به حل مسئله و تجزیه و تحلیل داده ها می پردازیم متحول کرده است.
یادگیری ماشینی با توانایی یادگیری از دادهها و پیشبینی یا تصمیمگیری، به یک ابزار ضروری در زمینههای مختلف، از مالی گرفته تا مراقبتهای بهداشتی تبدیل شده است.
با این حال، مانند هر ابزار دیگری، مدلهای یادگیری ماشین کامل نیستند و گاهی اوقات میتوانند نتایج نادرست یا غیرقابل اعتمادی ایجاد کنند.
یکی از عواملی که می تواند بر عملکرد مدل های یادگیری ماشین تاثیر بگذارد، واریانس است.
واریانس به حساسیت یک مدل به داده های آموزشی اشاره دارد.
به زبان ساده، اندازهگیری میکند که پیشبینیهای یک مدل زمانی که روی زیرمجموعههای مختلف دادههای آموزشی آموزش داده میشوند، چقدر تغییر میکنند.
یک مدل با واریانس بالا بیش از حد به داده های آموزشی حساس است که می تواند منجر به بیش از حد برازش شود.
تطبیق بیش از حد زمانی اتفاق میافتد که یک مدل دادههای آموزشی را خیلی خوب یاد میگیرد، تا جایی که نتواند به خوبی به دادههای جدید و دیده نشده تعمیم دهد.
این به این معنی است که مدل ممکن است به طور استثنایی روی داده های آموزشی عملکرد خوبی داشته باشد اما در پیش بینی های دقیق روی داده های جدید شکست بخورد.
مدلهای واریانس بالا بیش از حد پیچیده هستند و نویز یا نوسانات تصادفی در دادههای آموزشی را به جای الگوها یا روابط زیربنایی ثبت میکنند.
تأثیر واریانس بر عملکرد و تعمیم مدل را نمی توان اغراق کرد.
زمانی که یک مدل دارای واریانس بالا باشد، احتمالاً عملکرد پیشبینی ضعیفی روی دادههای جدید خواهد داشت.
این به این دلیل است که مدل اساسا داده های آموزشی را به جای یادگیری الگوهای زیربنایی حفظ کرده است.
در نتیجه، مدل ممکن است نتواند روابط واقعی بین ویژگیهای ورودی و متغیر هدف را به تصویر بکشد، که منجر به پیشبینیهای نادرست میشود.
برای پرداختن به موضوع واریانس بالا، می توان از تکنیک های مختلفی استفاده کرد.
یکی از رویکردهای رایج کاهش پیچیدگی مدل است.
این را می توان با محدود کردن تعداد ویژگی های مورد استفاده در مدل یا با استفاده از تکنیک های منظم سازی، مانند تنظیم L1 یا L2 انجام داد.
این تکنیکها، مدلهای پیچیده را جریمه میکنند و آنها را تشویق میکنند تا روی مهمترین ویژگیها تمرکز کنند و بیش از حد برازش را کاهش دهند.
روش دیگر برای کاهش واریانس افزایش میزان داده های آموزشی است.
با ارائه نمونههای متنوعتر به مدل، احتمال کمتر تطبیق آن با الگوهای خاص یا نویز در دادههای آموزشی وجود دارد.
این امر به ویژه در هنگام برخورد با مجموعه داده های کوچک، که در آن خطر بیش از حد برازش بیشتر است، مهم است.
اعتبار سنجی متقاطع تکنیک دیگری است که می تواند به کاهش تاثیر واریانس بر عملکرد مدل کمک کند.
با تقسیم دادههای آموزشی به زیر مجموعههای متعدد و آموزش مدل بر روی ترکیبهای مختلف این زیر مجموعهها، اعتبارسنجی متقابل تخمین قویتری از عملکرد مدل ارائه میکند.
این به شناسایی مدل هایی کمک می کند که نسبت به داده های آموزشی حساسیت کمتری دارند و به احتمال زیاد به داده های جدید تعمیم می یابند.
در نتیجه، واریانس نقش مهمی در عملکرد و تعمیم مدلهای یادگیری ماشین بازی میکند.
مدلهای با واریانس بالا مستعد برازش بیش از حد هستند و ممکن است در پیشبینی دقیق دادههای جدید شکست بخورند.
برای پرداختن به این موضوع می توان از تکنیک هایی مانند کاهش پیچیدگی مدل، افزایش میزان داده های آموزشی و استفاده از اعتبارسنجی متقابل استفاده کرد.
با درک و مدیریت واریانس، میتوانیم قابلیت اطمینان و اثربخشی مدلهای یادگیری ماشین را در کاربردهای مختلف بهبود بخشیم.

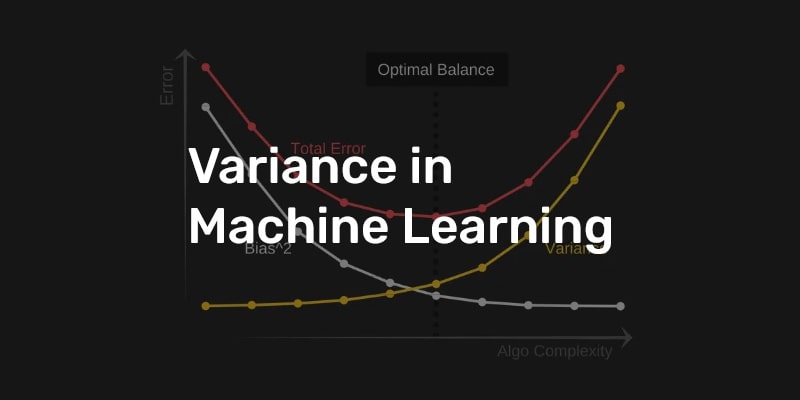
کاوش در مبادله بین تعصب و واریانس در یادگیری ماشین
یادگیری ماشین ابزار قدرتمندی است که صنایع مختلف، از مراقبت های بهداشتی گرفته تا امور مالی را متحول کرده است.
این به رایانه ها اجازه می دهد تا از داده ها یاد بگیرند و بدون برنامه ریزی صریح، پیش بینی یا تصمیم بگیرند.
با این حال، مانند هر ابزار دیگری، یادگیری ماشین محدودیت ها و چالش های خود را دارد.
یکی از چالشهای کلیدی در یادگیری ماشین، یافتن تعادل مناسب بین سوگیری و واریانس است.
سوگیری به خطای ارائه شده توسط مفروضات مدل اشاره دارد.
یک مدل با سوگیری بالا مشکل را بیش از حد ساده می کند و فرضیات قوی در مورد داده ها ایجاد می کند.
از سوی دیگر، واریانس به خطای ایجاد شده توسط حساسیت مدل به نوسانات در داده های آموزشی اشاره دارد.
یک مدل با واریانس بالا بیش از حد پیچیده است و بیش از حد با داده های آموزشی مطابقت دارد.
یافتن تعادل مناسب بین سوگیری و واریانس برای ساخت یک مدل یادگیری ماشینی خوب بسیار مهم است.
اگر یک مدل سوگیری بالایی داشته باشد، داده ها را پایین می آورد و نمی تواند الگوهای زیربنایی را بگیرد.
این منجر به عملکرد ضعیف در داده های آموزشی و آزمایشی می شود.
از سوی دیگر، اگر مدلی واریانس بالایی داشته باشد، با داده های آموزشی بیش از حد برازش می کند و روی داده های دیده نشده ضعیف عمل می کند.
این به عنوان overfitting شناخته می شود.
برای درک مبادله بین سوگیری و واریانس، بیایید نمونه ای از پیش بینی قیمت مسکن را در نظر بگیریم.
فرض کنید مجموعه داده ای از خانه ها با ویژگی هایی مانند اندازه، تعداد اتاق خواب و موقعیت مکانی داریم.
هدف ما ساخت مدلی است که بتواند قیمت یک خانه را با توجه به ویژگی های آن به طور دقیق پیش بینی کند.
اگر یک مدل رگرسیون خطی ساده را با تنها یک ویژگی مانند اندازه انتخاب کنیم، ممکن است بایاس بالا را معرفی کنیم.
این به این دلیل است که فرض می کنیم رابطه بین اندازه و قیمت خطی است.
با این حال، در واقعیت، ممکن است عوامل دیگری مانند مکان یا تعداد اتاق خواب ها نیز بر قیمت تأثیر بگذارد.
در نتیجه، مدل ما دارای سوگیری بالایی خواهد بود و قادر به گرفتن پیچیدگی داده ها نخواهد بود.
از سوی دیگر، اگر یک مدل پیچیده مانند یک شبکه عصبی عمیق با چندین لایه را انتخاب کنیم، ممکن است واریانس بالایی را معرفی کنیم.
این به این دلیل است که مدل بسیار انعطاف پذیر است و می تواند به خوبی با داده های آموزشی مطابقت داشته باشد.
با این حال، ممکن است با نویز یا نوسانات تصادفی دادهها نیز مطابقت داشته باشد که منجر به عملکرد ضعیف در دادههای دیده نشده میشود.
در این صورت مدل ما واریانس بالایی خواهد داشت و به خوبی به خانه های جدید تعمیم نمی یابد.
بنابراین، چگونه تعادل مناسب بین سوگیری و واریانس را پیدا کنیم؟ یک رویکرد استفاده از تکنیک های منظم سازی است.
منظم سازی یک عبارت جریمه به تابع هدف مدل اضافه می کند و آن را از تطبیق نویز در داده ها منصرف می کند.
این به کاهش واریانس مدل و بهبود عملکرد تعمیم آن کمک می کند.
روش دیگر استفاده از اعتبارسنجی متقابل است.
اعتبار سنجی متقابل شامل تقسیم داده ها به زیر مجموعه های متعدد، آموزش مدل بر روی برخی از زیر مجموعه ها و ارزیابی عملکرد آن در زیر مجموعه های باقی مانده است.
این به ما کمک می کند عملکرد مدل را بر روی داده های دیده نشده تخمین بزنیم و بهترین مدلی را انتخاب کنیم که هم سوگیری و هم واریانس را به حداقل می رساند.
در نتیجه، یافتن تعادل مناسب بین سوگیری و واریانس برای ساخت یک مدل یادگیری ماشین خوب بسیار مهم است.
سوگیری زیاد منجر به عدم تناسب می شود، در حالی که واریانس بالا منجر به بیش از حد برازش می شود.
منظم سازی و اعتبار سنجی متقابل دو تکنیکی هستند که می توانند به ما کمک کنند تا مبادله بهینه بین سوگیری و واریانس را پیدا کنیم.
با درک و مدیریت این مبادله، میتوانیم مدلهایی بسازیم که الگوهای زیربنایی دادهها را به دقت ثبت کنند و پیشبینیهای قابل اعتمادی را انجام دهند.
مطالعات موردی: نمونههای واقعی واریانس در مدلهای یادگیری ماشین
یادگیری ماشینی با برنامههای کاربردی از دستیارهای مجازی گرفته تا ماشینهای خودران، به بخشی جداییناپذیر از زندگی ما تبدیل شده است.
با این حال، مانند هر تکنولوژی، بدون نقص نیست.
یکی از رایجترین چالشها در یادگیری ماشین، واریانس است که به حساسیت یک مدل نسبت به دادههای آموزشی که در معرض آن قرار میگیرد، اشاره دارد.
در این مقاله، نمونههای واقعی واریانس در مدلهای یادگیری ماشین را بررسی میکنیم.
بیایید با یک مثال کلاسیک شروع کنیم: تشخیص هرزنامه.
تصور کنید در حال ساخت یک مدل یادگیری ماشینی هستید تا ایمیل ها را به عنوان هرزنامه یا غیر هرزنامه طبقه بندی کنید.
شما مجموعه داده بزرگی از ایمیلهای برچسبدار را جمعآوری میکنید و مدل خود را با استفاده از این دادهها آموزش میدهید.
با این حال، هنگامی که مدل خود را روی ایمیلهای جدید و دیده نشده آزمایش میکنید، متوجه میشوید که آنطور که انتظار میرود عملکرد خوبی ندارد.
این یک مورد واضح از واریانس است.
دلیل این تفاوت می تواند این باشد که داده های آموزشی به طور کامل نشان دهنده تنوع ایمیل هایی نیست که مدل شما در دنیای واقعی با آن مواجه می شود.
برای مثال، اگر دادههای آموزشی شما عمدتاً از ایمیلهای هرزنامه با سبک یا محتوای خاصی تشکیل شده باشد، مدل شما ممکن است برای تعمیم به انواع جدیدی از ایمیلهای هرزنامه مشکل داشته باشد.
این به عنوان overfitting شناخته می شود، که در آن مدل بیش از حد به داده های آموزشی تخصصی می شود و به خوبی تعمیم نمی یابد.
نمونه دیگری از واریانس را می توان در تشخیص تصویر یافت.
فرض کنید در حال آموزش مدلی برای تشخیص نژادهای مختلف سگ هستید.
شما مجموعه داده ای از تصاویر نژادهای مختلف سگ را جمع آوری می کنید و مدل خود را با استفاده از این داده ها آموزش می دهید.
با این حال، وقتی مدل خود را روی تصاویر جدید آزمایش می کنید، متوجه می شوید که اغلب نژادهای خاصی را به اشتباه طبقه بندی می کند.
این یک مورد دیگر از واریانس است.
دلیل این واریانس می تواند این باشد که داده های آموزشی تمام تغییرات احتمالی هر نژاد را پوشش نمی دهد.
به عنوان مثال، اگر دادههای آموزشی شما بیشتر شامل تصاویر سگها در محیطهای پر نور باشد، مدل شما ممکن است در تشخیص سگها در شرایط کم نور مشکل داشته باشد.
این به عنوان underfitting شناخته می شود، که در آن مدل نمی تواند پیچیدگی داده های دنیای واقعی را ثبت کند.
واریانس همچنین می تواند در وظایف پردازش زبان طبیعی، مانند تجزیه و تحلیل احساسات، ایجاد شود.
فرض کنید در حال ساخت مدلی برای طبقه بندی نقدهای فیلم به عنوان مثبت یا منفی هستید.
مجموعه داده ای از بررسی های برچسب گذاری شده را جمع آوری می کنید و مدل خود را با استفاده از این داده ها آموزش می دهید.
با این حال، وقتی مدل خود را بر روی بررسی های جدید آزمایش می کنید، متوجه می شوید که اغلب نظرات را با لحن طعنه آمیز یا کنایه آمیز طبقه بندی می کند.
این یک مورد دیگر از واریانس است.
دلیل این واریانس می تواند این باشد که داده های آموزشی شامل نمونه های کافی از بررسی های طعنه آمیز یا کنایه آمیز نمی شود.
در نتیجه، مدل شما ممکن است در درک تفاوت های ظریف زبان مشکل داشته باشد و چنین بررسی هایی را به اشتباه طبقه بندی کند.
این به عنوان سوگیری شناخته میشود، جایی که پیشبینیهای مدل تحت تأثیر سوگیریهای موجود در دادههای آموزشی است.
در نتیجه، واریانس یک چالش رایج در مدلهای یادگیری ماشین است.
این می تواند به روش های مختلفی مانند بیش از حد مناسب، عدم تناسب و سوگیری ظاهر شود.
مثالهای دنیای واقعی، مانند تشخیص هرزنامه، تشخیص تصویر، و تجزیه و تحلیل احساسات، تأثیر واریانس را بر عملکرد مدلهای یادگیری ماشین نشان میدهند.
برای غلبه بر واریانس، جمعآوری دادههای آموزشی متنوع و معرف و همچنین استفاده از تکنیکهایی مانند منظمسازی و افزایش دادهها بسیار مهم است.
با پرداختن به واریانس، میتوانیم قابلیت اطمینان و دقت مدلهای یادگیری ماشین را در برنامههای کاربردی دنیای واقعی بهبود بخشیم.
منبع » آکادمی اشکان مستوفی




