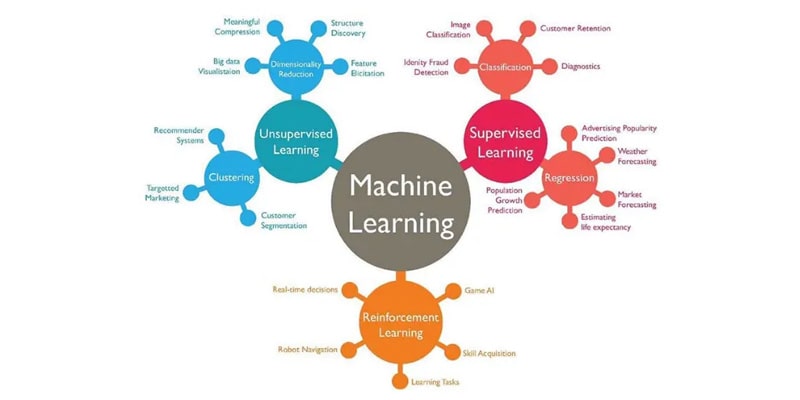
ماشین یادگیری یک زمینه جذاب است که در سال های اخیر توجه زیادی را به خود جلب کرده است. این شامل توسعه الگوریتمها و مدلهایی است که به رایانهها اجازه میدهد از دادهها یاد بگیرند و بدون برنامهریزی صریح، پیشبینی یا تصمیم بگیرند.
انواع مختلفی از یادگیری ماشینی وجود دارد که هر کدام ویژگی ها و کاربردهای منحصر به فرد خود را دارند. در این مقاله، ما بر روی یکی از رایج ترین انواع یادگیری ماشین تمرکز خواهیم کرد: یادگیری تحت نظارت.
Supervised learning
یادگیری نظارت شده نوعی از یادگیری ماشینی است که در آن الگوریتم از داده های برچسب دار یاد می گیرد.
دادههای برچسبگذاری شده به مجموعه دادهای اشاره دارد که در آن هر نقطه داده با یک برچسب یا مقدار خروجی مربوطه مرتبط است.
هدف از یادگیری تحت نظارت، آموزش مدلی است که بتواند مقدار خروجی را برای نقاط داده جدید و نادیده به دقت پیش بینی کند.
یکی از مزایای کلیدی یادگیری تحت نظارت این است که امکان توسعه مدل های پیش بینی را فراهم می کند.
این مدلها را میتوان برای پیشبینی یا طبقهبندی بر روی دادههای جدید و نادیده استفاده کرد.
به عنوان مثال، یک الگوریتم یادگیری نظارت شده می تواند بر روی مجموعه داده ای از ایمیل ها آموزش داده شود که هر ایمیل به عنوان هرزنامه یا غیر هرزنامه برچسب گذاری شود.
پس از آموزش، این مدل می تواند برای طبقه بندی ایمیل های جدید به عنوان هرزنامه یا غیر هرزنامه استفاده شود.
چندین الگوریتم محبوب در یادگیری تحت نظارت استفاده می شود، از جمله درخت تصمیم، جنگل های تصادفی، ماشین های بردار پشتیبان و شبکه های عصبی.
هر الگوریتم نقاط قوت و ضعف خود را دارد و انتخاب الگوریتم بستگی به مشکل خاصی دارد.
درختان تصمیم یک الگوریتم ساده و در عین حال قدرتمند هستند که در یادگیری نظارت شده استفاده می شود.
آنها با پارتیشن بندی بازگشتی داده ها بر اساس ویژگی های مختلف کار می کنند و ساختاری درخت مانند ایجاد می کنند.
هر گره داخلی درخت نشان دهنده یک تصمیم بر اساس یک ویژگی است، در حالی که هر گره برگ نشان دهنده یک برچسب کلاس یا مقدار خروجی است.
درخت های تصمیم به راحتی قابل تفسیر هستند و می توانند داده های دسته بندی و عددی را مدیریت کنند.
جنگل های تصادفی یک روش یادگیری گروهی است که چندین درخت تصمیم را برای پیش بینی ترکیب می کند.
هر درخت در جنگل تصادفی بر روی یک زیرمجموعه تصادفی از داده ها آموزش داده می شود و پیش بینی نهایی با تجمیع پیش بینی های همه درختان انجام می شود.
جنگل های تصادفی به دلیل استحکام و توانایی خود در مدیریت داده های با ابعاد بالا شناخته شده اند.
ماشین های بردار پشتیبان (SVM) یکی دیگر از الگوریتم های محبوب مورد استفاده در یادگیری نظارت شده است.
SVM ها با یافتن ابر صفحه بهینه که داده ها را به کلاس های مختلف جدا می کند، کار می کنند.
هایپرپلن طوری انتخاب می شود که حاشیه بین طبقات را به حداکثر می رساند.
SVM ها به ویژه در مواردی که داده ها به صورت خطی قابل تفکیک نیستند موثر هستند.
شبکه های عصبی دسته ای از الگوریتم ها هستند که از ساختار و عملکرد مغز انسان الهام گرفته شده اند.
آنها از گره های به هم پیوسته یا نورون ها تشکیل شده اند که در لایه ها سازماندهی شده اند.
هر نورون ورودی ها را می گیرد، محاسباتی را انجام می دهد و خروجی تولید می کند.
شبکه های عصبی قادر به یادگیری الگوهای پیچیده هستند و در طیف وسیعی از کاربردها از جمله تشخیص تصویر و گفتار موفق بوده اند.
در نتیجه، یادگیری نظارت شده یک نوع قدرتمند از یادگیری ماشینی است که امکان توسعه مدل های پیش بینی را فراهم می کند.
این شامل آموزش یک الگوریتم بر روی داده های برچسب گذاری شده و استفاده از آن برای پیش بینی یا طبقه بندی داده های جدید و نادیده است.
چندین الگوریتم محبوب در یادگیری تحت نظارت استفاده می شود، از جمله درخت تصمیم، جنگل های تصادفی، ماشین های بردار پشتیبان و شبکه های عصبی.
هر الگوریتم نقاط قوت و ضعف خود را دارد و انتخاب الگوریتم بستگی به مشکل خاصی دارد.
Unsupervised learning
یادگیری بدون نظارت نوعی از یادگیری ماشینی است که در آن الگوریتم الگوها و روابط در داده ها را بدون هیچ گونه راهنمایی یا برچسب صریح می آموزد.
برخلاف یادگیری تحت نظارت، که در آن الگوریتم با داده های برچسب گذاری شده برای یادگیری ارائه می شود، یادگیری بدون نظارت تنها بر ساختار ذاتی داده ها متکی است.
این امر باعث میشود که هنگام برخورد با مجموعه دادههای بزرگ که برچسبگذاری دادهها زمانبر یا غیرعملی باشد، بسیار مفید است.
یکی از مزایای اصلی یادگیری بدون نظارت، توانایی آن در کشف الگوها و ساختارهای پنهان در داده ها است. با تجزیه و تحلیل روابط بین نقاط داده، الگوریتم های یادگیری بدون نظارت می توانند خوشه ها یا گروه هایی از نقاط داده مشابه را شناسایی کنند.
این می تواند در برنامه های مختلف مانند تقسیم بندی مشتری، تشخیص ناهنجاری و سیستم های توصیه مفید باشد.
خوشه بندی یکی از رایج ترین تکنیک های مورد استفاده در یادگیری بدون نظارت است.
این شامل گروه بندی نقاط داده مشابه بر اساس ویژگی ها یا ویژگی های آنها است. به عنوان مثال، در تقسیم بندی مشتری، الگوریتم های خوشه بندی می توانند مشتریانی را با رفتار خرید یا جمعیت شناسی مشابه گروه بندی کنند.
سپس می توان از این اطلاعات برای تنظیم استراتژی های بازاریابی یا شخصی سازی توصیه ها استفاده کرد.
تکنیک دیگری که در یادگیری بدون نظارت استفاده می شود کاهش ابعاد است.
این شامل کاهش تعداد ویژگی ها یا متغیرها در یک مجموعه داده و در عین حال حفظ اطلاعات ضروری آن است.
کاهش ابعاد می تواند به ویژه هنگام برخورد با داده های با ابعاد بالا مفید باشد، زیرا به حذف نویز و افزونگی کمک می کند.
این می تواند منجر به بهبود عملکرد و کارایی در کارهای بعدی یادگیری ماشین شود.
یکی از الگوریتم های محبوبی که برای کاهش ابعاد استفاده می شود، آنالیز مؤلفه اصلی (PCA) است.
PCA جهت هایی را که داده ها در آنها بیشترین تغییر را دارند شناسایی می کند و داده ها را بر روی این جهت ها پخش می کند و در نتیجه نمایشی با ابعاد پایین تر ایجاد می کند. این می تواند در تجسم و درک مجموعه داده های پیچیده مفید باشد.
تشخیص ناهنجاری یکی دیگر از کاربردهای مهم یادگیری بدون نظارت است.
ناهنجاری ها نقاط داده ای هستند که به طور قابل توجهی از هنجار یا رفتار مورد انتظار منحرف می شوند.
با یادگیری الگوهای عادی در داده ها، الگوریتم های یادگیری بدون نظارت می توانند ناهنجاری ها را شناسایی و علامت گذاری کنند.
این می تواند در حوزه های مختلفی مانند تشخیص تقلب، تشخیص نفوذ شبکه و کنترل کیفیت ساخت مفید باشد.
یادگیری بدون نظارت نیز نقش مهمی در سیستم های توصیه ایفا می کند. هدف این سیستم ها ارائه توصیه های شخصی به کاربران بر اساس ترجیحات و رفتار آنهاست.
با تجزیه و تحلیل الگوها و شباهتها در دادههای کاربر، الگوریتمهای یادگیری بدون نظارت میتوانند گروههایی از کاربران را با علایق مشابه شناسایی کرده و بر اساس ترجیحات کاربران مشابه توصیههایی ارائه کنند. این می تواند تجربه کاربر را افزایش دهد و تعامل را افزایش دهد.
در نتیجه، یادگیری بدون نظارت یک تکنیک قدرتمند در یادگیری ماشینی است که به رایانهها اجازه میدهد از دادههای بدون برچسب یاد بگیرند.
این امکان کشف الگوها و ساختارهای پنهان در داده ها را فراهم می کند و آن را در کاربردهای مختلف مانند خوشه بندی، کاهش ابعاد، تشخیص ناهنجاری و سیستم های توصیه مفید می کند.
با استفاده از ساختار ذاتی داده ها، الگوریتم های یادگیری بدون نظارت می توانند بینش های ارزشمندی را ارائه دهند و فرآیندهای تصمیم گیری را بهبود بخشند.
Reinforcement learning
یادگیری تقویتی: کاوش در زمینه پویا یادگیری ماشین و تصمیم گیری یادگیری ماشین روشی را که ما به حل مسئله و تصمیم گیری می پردازیم متحول کرده است.
یکی از مهیج ترین و پویاترین شاخه های یادگیری ماشینی، یادگیری تقویتی است. در این مقاله به بررسی مفهوم یادگیری تقویتی، کاربردهای آن و پتانسیل آن برای آینده خواهیم پرداخت.
یادگیری تقویتی نوعی یادگیری ماشینی است که بر نحوه تصمیم گیری یک عامل برای به حداکثر رساندن پاداش تمرکز دارد.
برخلاف سایر انواع یادگیری ماشینی، یادگیری تقویتی به مجموعه داده ای با نمونه های برچسب دار نیاز ندارد.
در عوض، عامل از طریق آزمون و خطا یاد میگیرد و بازخوردی را در قالب پاداش یا تنبیه دریافت میکند.
ایده اصلی پشت یادگیری تقویتی این است که عامل با محیط تعامل داشته باشد، اقداماتی انجام دهد و بر اساس آن اقدامات بازخورد دریافت کند.
هدف عامل یادگیری خط مشی است، که نقشه برداری از حالت ها به اقدامات است، که پاداش تجمعی را در طول زمان به حداکثر می رساند.
این فرآیند اغلب به عنوان یک فرآیند تصمیم گیری مارکوف (MDP) نشان داده می شود، که در آن عامل بر اساس اقداماتی که انجام می دهد از یک حالت به حالت دیگر منتقل می شود.
یکی از شناخته شده ترین کاربردهای یادگیری تقویتی در زمینه رباتیک است. ربات های مجهز به الگوریتم های یادگیری تقویتی می توانند با تعامل با محیط خود انجام وظایف پیچیده را بیاموزند.
به عنوان مثال، یک ربات می تواند با کاوش در مسیرهای مختلف و دریافت پاداش برای رسیدن به هدف، حرکت در پیچ و خم را یاد بگیرد.
با گذشت زمان، ربات خط مشی بهینه را برای پیمایش در پیچ و خم، حتی در حضور موانع یا شرایط متغیر، یاد می گیرد.
یکی دیگر از کاربردهای هیجان انگیز یادگیری تقویتی در زمینه بازی است.
الگوریتمهای یادگیری تقویتی برای آموزش عواملی استفاده شده است که میتوانند بازیهایی مانند شطرنج، Go و پوکر را در سطحی مافوق بشری انجام دهند.
این عوامل با انجام هزاران بازی علیه خود یاد می گیرند و به تدریج استراتژی ها و توانایی های تصمیم گیری خود را بهبود می بخشند. موفقیت این الگوریتم ها قدرت یادگیری تقویتی را در محیط های پیچیده و استراتژیک نشان داده است.
یادگیری تقویتی همچنین در زمینه هایی مانند مالی، مراقبت های بهداشتی و وسایل نقلیه خودران کاربرد دارد.
در امور مالی، الگوریتمهای یادگیری تقویتی میتوانند برای بهینهسازی استراتژیهای معاملاتی و مدیریت پورتفولیو استفاده شوند.
در مراقبت های بهداشتی، یادگیری تقویتی می تواند به توصیه های درمانی شخصی و کشف دارو کمک کند.
در وسایل نقلیه خودران، یادگیری تقویتی می تواند به خودروهای خودران این امکان را بدهد که یاد بگیرند چگونه ایمن و کارآمد در جاده ها حرکت کنند.
در حالی که یادگیری تقویتی در حوزه های مختلف نویدبخش است، اما با چالش های خود نیز همراه است.
یکی از چالش های اصلی، مبادله اکتشاف و بهره برداری است.
عامل باید بین کاوش اقدامات جدید برای کشف استراتژی های بهتر و بهره برداری از دانش فعلی برای به حداکثر رساندن پاداش ها تعادل برقرار کند.
یافتن تعادل مناسب برای یادگیری کارآمد بسیار مهم است.
چالش دیگر، نفرین ابعاد است. با افزایش تعداد حالت ها و اقدامات، فرآیند یادگیری پیچیده تر و از نظر محاسباتی گران تر می شود.
محققان به طور مداوم بر روی توسعه الگوریتمها و تکنیکهایی کار میکنند تا به این چالشها رسیدگی کنند و یادگیری تقویتی را مقیاسپذیرتر و کارآمدتر کنند.
در نتیجه، یادگیری تقویتی یک زمینه جذاب و پویا از یادگیری ماشینی است که بر تصمیم گیری در یک محیط تعاملی تمرکز دارد.
کاربردهای آن از رباتیک و بازی تا امور مالی و مراقبت های بهداشتی را شامل می شود.
در حالی که چالش هایی برای غلبه بر وجود دارد، پتانسیل یادگیری تقویتی برای حل مسائل پیچیده و بهینه سازی تصمیم گیری بسیار زیاد است.
از آنجایی که محققان همچنان مرزهای این حوزه را پیش می برند، می توان انتظار داشت که در آینده شاهد پیشرفت های هیجان انگیزتری باشیم.

Semi-supervised learning
یادگیری ماشینی زمینه ای است که به سرعت در حال رشد است که صنایع مختلف را متحول کرده است.
این شامل توسعه الگوریتمها و مدلهایی است که رایانهها را قادر میسازد تا از دادهها یاد بگیرند و بدون برنامهریزی صریح، پیشبینی یا تصمیم بگیرند.
یکی از محبوب ترین انواع یادگیری ماشینی، یادگیری تحت نظارت است که در آن الگوریتم بر روی داده های برچسب دار آموزش داده می شود.
با این حال، نوع دیگری از یادگیری ماشینی به نام یادگیری نیمه نظارتی وجود دارد که مزایای داده های برچسب دار و بدون برچسب را با هم ترکیب می کند.
در یادگیری نظارت شده، الگوریتم با مجموعه داده ای ارائه می شود که قبلاً برچسب گذاری شده است.
این بدان معنی است که هر نقطه داده با یک کلاس یا دسته خاص مرتبط است.
به عنوان مثال، در یک کار طبقهبندی ایمیلهای هرزنامه، به الگوریتم مجموعهای از ایمیلها داده میشود که هر ایمیل به عنوان هرزنامه یا غیر هرزنامه برچسبگذاری شده است.
الگوریتم از این دادههای برچسبگذاری شده یاد میگیرد و سپس روی دادههای جدید و دیده نشده پیشبینی میکند.
در حالی که یادگیری تحت نظارت موثر است، محدودیت های خود را دارد. به دست آوردن داده های برچسب دار می تواند گران و زمان بر باشد.
در بسیاری از سناریوهای دنیای واقعی، دادههای بدون برچسب فراوانی وجود دارد، اما برچسبگذاری دستی آن غیرعملی است. اینجاست که یادگیری نیمه نظارتی وارد می شود.
یادگیری نیمه نظارت شده از داده های برچسب دار و بدون برچسب برای بهبود عملکرد الگوریتم استفاده می کند.
ایده این است که الگوریتم میتواند از مقدار کمی دادههای برچسبگذاریشده یاد بگیرد و در عین حال از حجم وسیعی از دادههای بدون برچسب نیز استفاده کند. با این کار می تواند تعمیم بهتری داشته باشد و پیش بینی های دقیق تری انجام دهد.
یکی از رویکردهای رایج در یادگیری نیمه نظارتی، استفاده از داده های برچسب گذاری شده برای ساخت یک مدل اولیه است.
سپس از این مدل برای پیشبینی دادههای بدون برچسب استفاده میشود. پیشبینیها بهعنوان شبه برچسبها در نظر گرفته میشوند و الگوریتم بر روی دادههای برچسبگذاری شده و شبه برچسبگذاری شده آموزش داده میشود.
این فرآیند به طور مکرر تکرار می شود و مدل در هر تکرار اصلاح می شود.
رویکرد دیگر در یادگیری نیمه نظارتی استفاده از داده های بدون برچسب برای ایجاد یک محدودیت همواری است.
ایده این است که نقاط داده مشابه باید دارای برچسب های مشابه باشند. با اعمال این محدودیت،
الگوریتم میتواند یاد بگیرد که پیشبینیهایی مطابق با دادههای بدون برچسب داشته باشد.
این رویکرد به ویژه زمانی مفید است که داده های برچسب گذاری شده کمیاب یا پر سر و صدا هستند.
یادگیری نیمه نظارتی با موفقیت در حوزه های مختلف اعمال شده است.
به عنوان مثال، در کارهای طبقه بندی تصاویر، جایی که برچسب زدن تصاویر می تواند زمان بر باشد، یادگیری نیمه نظارتی نتایج امیدوارکننده ای را نشان داده است.
به طور مشابه، در وظایف پردازش زبان طبیعی، که در آن مقادیر زیادی از داده های متنی بدون برچسب در دسترس است، یادگیری نیمه نظارتی در بهبود عملکرد الگوریتم ها موثر بوده است.
با این حال، توجه به این نکته مهم است که یادگیری نیمه نظارتی راه حلی برای همه نیست.
زمانی که مقدار کمی داده برچسب دار و مقدار زیادی داده بدون برچسب وجود داشته باشد بهترین عملکرد را دارد.
اگر دادههای برچسبگذاری شده از قبل کافی باشد، یادگیری تحت نظارت ممکن است مناسبتر باشد. علاوه بر این، کیفیت داده های بدون برچسب نیز می تواند بر عملکرد الگوریتم های یادگیری نیمه نظارت شده تأثیر بگذارد.
در نتیجه، یادگیری نیمه نظارت شده یک تکنیک قدرتمند است که مزایای داده های برچسب دار و بدون برچسب را ترکیب می کند.
این به الگوریتمها اجازه میدهد تا از دادههای برچسبگذاریشده محدود یاد بگیرند و در عین حال از حجم وسیعی از دادههای بدون برچسب موجود نیز استفاده کنند.
با انجام این کار، می تواند عملکرد و قابلیت های تعمیم مدل های یادگیری ماشین را بهبود بخشد.
در حالی که محدودیتهای خود را دارد و ممکن است برای همه سناریوها مناسب نباشد، یادگیری نیمه نظارتی در حوزههای مختلف نویدبخش است و همچنان به عنوان یک حوزه تحقیقاتی فعال در زمینه یادگیری ماشینی است.
Deep learning
یادگیری عمیق: A شیرجه عمیق به شبکه های عصبی و کاربردهای آنها در یادگیری ماشینی یادگیری ماشینی روش برخورد ما با مسائل پیچیده و پیشبینی را متحول کرده است.
یکی از قوی ترین و پرکاربردترین تکنیک ها در یادگیری ماشینی، یادگیری عمیق است که مبتنی بر شبکه های عصبی است.
در این مقاله، به بررسی عمیق شبکههای عصبی میپردازیم و کاربردهای آنها را در یادگیری ماشین بررسی میکنیم.
شبکه های عصبی نوعی مدل یادگیری ماشینی هستند که از مغز انسان الهام گرفته شده است.
آنها از گره های به هم پیوسته به نام نورون ها تشکیل شده اند که در لایه هایی سازماندهی شده اند.
هر نورون ورودی ها را می گیرد، محاسباتی را انجام می دهد و خروجی تولید می کند.
خروجی های یک لایه به عنوان ورودی لایه بعدی عمل می کند و به شبکه اجازه می دهد تا الگوها و روابط پیچیده در داده ها را بیاموزد.
یکی از مزایای کلیدی شبکه های عصبی توانایی آنها در یادگیری خودکار ویژگی ها از داده های خام است.
الگوریتمهای یادگیری ماشین سنتی به مهندسی ویژگیهای دستی نیاز دارند، جایی که کارشناسان دامنه ویژگیهای مرتبط را شناسایی میکنند.
در مقابل، شبکههای عصبی میتوانند این ویژگیها را مستقیماً از دادهها یاد بگیرند و در زمان و تلاش صرفهجویی کنند.
یادگیری عمیق به شبکه های عصبی با لایه های مخفی متعدد اشاره دارد.
این معماری های عمیق شبکه را قادر می سازد تا نمایش های سلسله مراتبی داده ها را بیاموزد.
هر لایه ویژگی های انتزاعی فزاینده ای را می آموزد و سطوح مختلفی از پیچیدگی را به تصویر می کشد.
این نمایش سلسله مراتبی به مدل های یادگیری عمیق اجازه می دهد تا در کارهایی مانند تشخیص تصویر و گفتار برتر باشند.
شبکههای عصبی کانولوشنال
شبکههای عصبی کانولوشنال (CNN) نوعی مدل یادگیری عمیق هستند که معمولاً برای کارهای تشخیص تصویر استفاده میشوند.
CNN ها برای پردازش داده ها با ساختار شبکه ای مانند تصاویر طراحی شده اند.
آنها از لایه های کانولوشن برای استخراج الگوهای محلی و روابط فضایی از ورودی استفاده می کنند.
با قرار دادن چندین لایه کانولوشن، CNN ها می توانند ویژگی های بصری پیچیده را بیاموزند و تصاویر را با دقت بالا طبقه بندی کنند.
شبکه های عصبی بازگشتی
شبکه های عصبی بازگشتی (RNN) نوع دیگری از مدل های یادگیری عمیق هستند که در پردازش متوالی داده ها برتری دارند.
برخلاف شبکههای عصبی پیشخور، که ورودیها را بهطور مستقل پردازش میکنند، RNNها دارای اتصالاتی هستند که به اطلاعات اجازه میدهند در چرخهها جریان پیدا کنند.
این ساختار چرخه ای RNN ها را قادر می سازد تا وابستگی های زمانی را در داده ها ثبت کنند و آنها را برای کارهایی مانند پردازش زبان طبیعی و تشخیص گفتار مناسب می کند.
شبکه های متخاصم مولد
شبکه های متخاصم مولد (GANs) یک برنامه جذاب از یادگیری عمیق هستند.
GAN ها از دو شبکه عصبی تشکیل شده اند: یک مولد و یک تشخیص دهنده. شبکه مولد یاد می گیرد که داده های مصنوعی تولید کند که شبیه داده های واقعی است، در حالی که شبکه تشخیص دهنده یاد می گیرد بین داده های واقعی و جعلی تمایز قائل شود.
از طریق یک فرآیند آموزش متخاصم، شبکههای مولد و تمایز به طور مکرر بهبود مییابند و منجر به دادههای مصنوعی بسیار واقعی میشوند.
یادگیری عمیق در حوزه های مختلف کاربرد پیدا کرده است.
در مراقبت های بهداشتی، مدل های یادگیری عمیق برای تجزیه و تحلیل تصویر پزشکی، تشخیص بیماری و کشف دارو استفاده شده است.
در امور مالی، یادگیری عمیق برای پیش بینی بازار سهام، کشف تقلب و معاملات الگوریتمی به کار گرفته شده است.
در رانندگی خودران، مدلهای یادگیری عمیق برای تشخیص اشیا، تشخیص خط و برنامهریزی مسیر استفاده شدهاند.
در نتیجه، یادگیری عمیق، مبتنی بر شبکه های عصبی، یک تکنیک قدرتمند در یادگیری ماشین است.
توانایی آن در یادگیری خودکار ویژگی ها از داده های خام و نمایش سلسله مراتبی آن از الگوهای پیچیده، آن را برای طیف گسترده ای از برنامه ها مناسب می کند.
از تشخیص تصویر گرفته تا پردازش زبان طبیعی، یادگیری عمیق این پتانسیل را دارد که صنایع مختلف را متحول کند و راه را برای سیستمهای هوش مصنوعی پیشرفتهتر هموار کند.
منبع » آکادمی اشکان مستوفی




