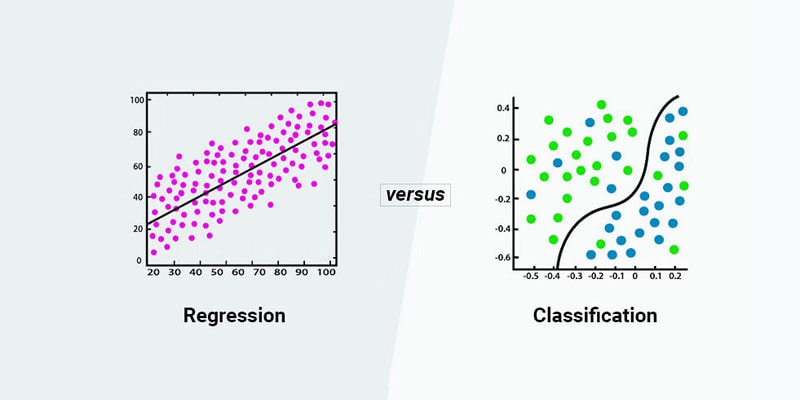
عمده ترین تفاوت مدل های طبقه بندی و رگرسیون در یادگیری ماشین این است که مدلهای طبقهبندی برای پیشبینی دستهها یا برچسبها استفاده میشوند، در حالی که مدلهای رگرسیون برای پیشبینی مقادیر پیوسته استفاده میشوند.
در ادامه با آکادمی اشکان مستوفی به بررسی کامل این دو مدل خواهیم پرداخت.
تفاوت مدل های طبقه بندی و رگرسیون در یادگیری ماشین
در یادگیری ماشین، دو نوع مدل مهم و پرکاربرد وجود دارد که به طور گسترده در حل مسائل مختلف استفاده میشوند: مدلهای طبقهبندی و مدلهای رگرسیون.
این دو نوع مدل اصولا برای دو نوع مسئله متفاوت استفاده میشوند و تفاوتهای اساسی بین آنها وجود دارد.
یکی از تفاوتهای اساسی بین مدلهای طبقهبندی و رگرسیون، نوع مسئله است که آنها برای حل آنها طراحی شدهاند.
در مدلهای طبقهبندی، هدف این است که دادهها را به دستههای مختلف تقسیم کنیم و یک مدل برای پیشبینی دستهای که یک نمونه جدید به آن تعلق دارد، ایجاد کنیم.
از سوی دیگر، در مدلهای رگرسیون، هدف این است که یک رابطه عددی بین ورودیها و خروجیها برقرار کنیم و یک مدل برای پیشبینی یک مقدار پیوسته بر اساس ورودیهای داده شده ایجاد کنیم.
یک تفاوت دیگر بین این دو نوع مدل، نوع خروجی است که تولید میکنند.
در مدلهای طبقهبندی، خروجی مدل یک برچسب یا دسته است که نمایانگر دستهای است که نمونه ورودی به آن تعلق دارد.
از سوی دیگر، در مدلهای رگرسیون، خروجی مدل یک مقدار پیوسته است که نمایانگر پیشبینی شده برای ورودی داده شده است.
در نهایت، یک تفاوت دیگر بین این دو نوع مدل، معیار ارزیابی عملکرد آنها است.
در مدلهای طبقهبندی، معیارهایی مانند دقت، صحت و فراخوانی برای ارزیابی عملکرد مدل استفاده میشوند، در حالی که در مدلهای رگرسیون، معیارهایی مانند خطای میانگین مربعات و ضریب تعیین برای ارزیابی عملکرد مدل استفاده میشوند.
بنابراین، با توجه به تفاوتهای اساسی بین مدلهای طبقهبندی و رگرسیون، انتخاب مناسب بین این دو نوع مدل بستگی به نوع مسئله و نوع دادههای مورد استفاده دارد.
انتخاب صحیح بین این دو نوع مدل میتواند به بهبود عملکرد و دقت پیشبینی مدل کمک کند.
کاربردهای مختلف مدلهای طبقهبندی و رگرسیون در صنایع مختلف
مدلهای طبقهبندی و رگرسیون دو نوع مدل مهم در یادگیری ماشین هستند که در صنایع مختلف استفاده میشوند.
این دو نوع مدل به دلیل ویژگیها و کاربردهای متفاوتی که دارند، در حل مسائل مختلف مورد استفاده قرار میگیرند.
مدلهای طبقهبندی به دستهبندی دادهها بر اساس ویژگیهای مختلف از آنها میپردازند.
به عبارت دیگر، این مدلها سعی دارند دادهها را به گروههای مختلف تقسیم کنند.
از مدلهای طبقهبندی برای پیشبینی یک متغیر کیفی مانند بلی یا خیر، دستهبندی تصاویر، تشخیص بیماریها و غیره استفاده میشود.
از سوی دیگر، مدلهای رگرسیون برای پیشبینی یک متغیر پیوسته استفاده میشوند.
این مدلها سعی دارند رابطه بین ورودیها و خروجیها را مدلسازی کنند.
به عبارت دیگر، آنها سعی میکنند یک تابع ریاضی برای پیشبینی یک متغیر پیوسته از دادههای ورودی بسازند.
مدلهای رگرسیون برای پیشبینی قیمتها، تخمین مقدار یک متغیر پیوسته، پیشبینی بازدهی سهام و غیره استفاده میشوند.
در عمل، مدلهای طبقهبندی و رگرسیون ممکن است در یک مسئله خاص به صورت ترکیبی استفاده شوند.
به عنوان مثال، در پیشبینی قیمت خانه، مدلهای طبقهبندی ممکن است برای تشخیص خانههای فروشی و اجارهای استفاده شوند، در حالی که مدلهای رگرسیون برای تخمین قیمت خانه استفاده میشوند.
بنابراین، مدلهای طبقهبندی و رگرسیون هر کدام ویژگیها و کاربردهای خاص خود را دارند و بر اساس نوع مسئله و دادههای موجود، انتخاب مناسب بین این دو نوع مدل بسیار مهم است.

الگوریتمهای محبوب برای مدلسازی طبقهبندی و رگرسیون
در علم داده و یادگیری ماشین، دو نوع مدل محبوب برای پیشبینی و تحلیل دادهها استفاده میشود: الگوریتمهای طبقهبندی و الگوریتمهای رگرسیون.
این دو نوع الگوریتم از یکدیگر متفاوت هستند و برای مسائل مختلف استفاده میشوند.
الگوریتمهای طبقهبندی به ما کمک میکنند تا دادهها را به دستههای مختلف تقسیم کنیم.
به عبارت دیگر، این الگوریتمها به ما میگویند که یک نمونه خاص از دادهها به کدام دسته تعلق دارد.
برای مثال، اگر ما بخواهیم یک الگوریتم طبقهبندی برای تشخیص ایمیلهای اسپم ایجاد کنیم، این الگوریتم به ما میگوید که هر ایمیل وارد شده به دسته ایمیلهای اسپم یا غیر اسپم تعلق دارد.
از سوی دیگر، الگوریتمهای رگرسیون برای پیشبینی یک مقدار پیوسته استفاده میشوند.
به عبارت دیگر، این الگوریتمها به ما کمک میکنند تا یک رابطه بین ورودیها و خروجیها را پیدا کنیم.
برای مثال، اگر ما بخواهیم قیمت یک خانه را بر اساس ویژگیهای مختلف آن پیشبینی کنیم، از یک الگوریتم رگرسیون استفاده میکنیم تا یک مدل پیشبینی برای ما ایجاد کند.
با این توضیحات، میتوان فهمید که الگوریتمهای طبقهبندی و رگرسیون از هم متفاوت هستند و برای مسائل مختلف استفاده میشوند.
الگوریتمهای طبقهبندی به ما کمک میکنند تا دادهها را به دستههای مختلف تقسیم کنیم، در حالی که الگوریتمهای رگرسیون برای پیشبینی یک مقدار پیوسته استفاده میشوند.
انتخاب الگوریتم مناسب برای هر مسئله بسیار مهم است و باید با دقت انجام شود تا به نتایج دقیق و قابل اعتماد برسیم.
روشهای ارزیابی عملکرد مدلهای طبقهبندی و رگرسیون
در ماشین لرنینگ، دو نوع مدل مهم برای پیشبینی و تحلیل دادهها استفاده میشود: مدلهای طبقهبندی و مدلهای رگرسیون.
این دو نوع مدل به دو روش مختلف برای ارزیابی عملکرد خود نیاز دارند.
روشهای ارزیابی عملکرد مدلهای طبقهبندی معمولاً بر اساس معیارهایی مانند دقت، حساسیت، و ویژگیهای دیگر انجام میشود.
برای مثال، اگر یک مدل طبقهبندی برای تشخیص بیماریهای قلبی آموزش داده شود، دقت مدل در تشخیص بیماریها میتواند به عنوان یک معیار ارزیابی مورد استفاده قرار گیرد.
همچنین، معیارهای دیگری مانند حساسیت (توانایی تشخیص بیماری در بیماران واقعی) و ویژگیهای دیگر نیز میتوانند برای ارزیابی عملکرد مدلهای طبقهبندی استفاده شوند.
از سوی دیگر، روشهای ارزیابی عملکرد مدلهای رگرسیون بر اساس معیارهایی مانند میانگین مربعات خطا (MSE)، ضریب تعیین (R-squared)، و سایر معیارهای مشابه انجام میشود.
به عنوان مثال، اگر یک مدل رگرسیون برای پیشبینی قیمت خانهها آموزش داده شود، MSE میتواند به عنوان یک معیار ارزیابی برای اندازهگیری دقت پیشبینیها استفاده شود.
بنابراین، ارزیابی عملکرد مدلهای طبقهبندی و رگرسیون از معیارهای مختلفی برای اندازهگیری دقت و کارایی مدلها استفاده میکند.
انتخاب معیار مناسب برای ارزیابی مدل بستگی به نوع دادهها و مسئله مورد نظر دارد.
به عنوان یک دادهکاویگر یا محقق در زمینه ماشین لرنینگ، اهمیت انتخاب معیار مناسب برای ارزیابی مدلها را در نظر داشته باشید تا بهترین تصمیمها را برای تحلیل دادهها و پیشبینی نتایج بگیرید.
چالشها و مشکلات معمول در استفاده از مدلهای طبقهبندی و رگرسیون در عملآوریهای واقعی
استفاده از مدلهای طبقهبندی و رگرسیون در مسائل مربوط به یادگیری ماشین میتواند به طور قابل توجهی به بهبود عملکرد سیستمهای هوش مصنوعی کمک کند.
اما در عملآوریهای واقعی، ممکن است با چالشها و مشکلاتی روبهرو شویم که باید آنها را مدیریت کنیم.
یکی از چالشهای اصلی در استفاده از مدلهای طبقهبندی و رگرسیون، انتخاب ویژگیهای مناسب برای آموزش مدل است.
انتخاب ویژگیهای نامناسب میتواند منجر به بیشبرازش یا کمبرازش مدل شود و عملکرد آن را تحت تأثیر قرار دهد.
برای حل این مشکل، باید به دقت و با تجربه ویژگیهای مناسب را انتخاب کرد و آنها را به مدل وارد کرد.
یک مشکل دیگر که ممکن است در استفاده از مدلهای طبقهبندی و رگرسیون پیش بیاید، نویز و دادههای پرت است.
دادههای پرت میتوانند تأثیر زیادی بر عملکرد مدل داشته باشند و باعث افزایش خطا در پیشبینیها شوند.
برای مدیریت این مشکل، میتوان از روشهای پیشپردازش داده مانند حذف دادههای پرت یا استفاده از روشهای نرمالسازی و استانداردسازی استفاده کرد.
در نهایت، یکی از چالشهای دیگر در استفاده از مدلهای طبقهبندی و رگرسیون، تعمیمپذیری مدل به دادههای جدید است.
ممکن است مدلی که با دادههای آموزشی خوب عمل میکند، با دادههای جدید خوب عمل نکند و این مشکل معمولاً به عدم تعمیمپذیری مدل برمیگردد.
برای حل این مشکل، باید از روشهای ارزیابی مدل و اعتبارسنجی استفاده کرد و مدل را بهبود داد.
به طور کلی، استفاده از مدلهای طبقهبندی و رگرسیون در عملآوریهای واقعی میتواند با چالشها و مشکلاتی همراه باشد که باید با دقت و تجربه مدیریت شوند تا به نتایج دقیق و قابل اعتمادی دست یابیم.
منبع » آکادمی اشکان مستوفی




