الگوریتم K-Nearest Neighbor یکی از محبوبترین الگوریتمهای یادگیری ماشین است که در حوزه طبقه بندی و پیشبینی استفاده میشود.
این الگوریتم بر اصل سادهای کار میکند: دادههای جدید را بر اساس شباهت آنها با دادههای موجود در مجموعه آموزش دستهبندی میکند.
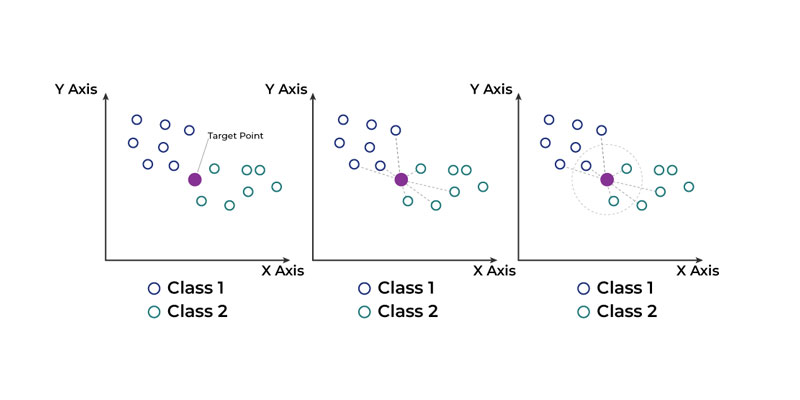
الگوریتم k-nearest neighbor در یادگیری ماشین
در اصول عملکرد الگوریتم K-Nearest Neighbor، ابتدا باید یک مجموعه داده آموزشی را داشته باشیم که شامل دادههای ورودی و برچسبهای متناظر با آنها است.
سپس، برای هر داده جدیدی که میخواهیم دستهبندی کنیم، ابتدا فاصله آن با تمام دادههای موجود در مجموعه آموزش را محاسبه میکنیم.
سپس، K دادهی نزدیکترین به داده جدید را انتخاب میکنیم.
این K نیز یک پارامتر قابل تنظیم است که تعداد دادههایی است که برای پیشبینی دستهبندی استفاده میشود.
سپس، با توجه به برچسبهای این K دادهی نزدیکترین، برچسب داده جدید را تعیین میکنیم.
از جمله مزایای این الگوریتم میتوان به سادگی پیادهسازی، عدم نیاز به فرضیات خاص در مورد دادهها، و قابلیت استفاده در مسائل غیرخطی اشاره کرد.
اما این الگوریتم نیز دارای محدودیتهایی است، از جمله حساسیت به دادههای پرت، نیاز به محاسبات زیاد برای پیشبینی دستهبندی، و عدم قابلیت استفاده در مجموعههای داده بزرگ.
با این حال، الگوریتم K-Nearest Neighbor همچنان یکی از ابزارهای مهم و موثر در حوزه یادگیری ماشین است که با استفاده از آن میتوان به دقت بالا و عملکرد خوبی در پیشبینی دستهبندی دادهها دست یافت.
مزایا و معایب استفاده از الگوریتم K-Nearest Neighbor
این الگوریتم بر اساس شباهت دادهها به یکدیگر عمل میکند و برای پیشبینی برچسب دادههای جدید از دادههای مشابه قبلی استفاده میکند.
یکی از مزایای اصلی استفاده از الگوریتم KNN این است که بحثی از آموزش مدل ندارد و به سرعت قابل استفاده است.
همچنین، این الگوریتم برای دادههایی که توزیع آنها پیچیده است، عملکرد خوبی دارد.
علاوه بر این، KNN یک الگوریتم غیرپارامتری است که به طور مستقیم به تعداد دادهها و فاصله آنها از یکدیگر وابسته است، بنابراین برای دادههای غیرخطی مناسب است.
اما از طرف دیگر، یکی از معایب اصلی استفاده از KNN این است که برای پیشبینی برچسب دادههای جدید نیاز به محاسبه فاصله آنها از تمام دادههای موجود دارد که ممکن است زمانبر باشد، به ویژه برای مجموعه دادههای بزرگ.
همچنین، این الگوریتم حساس به دادههای پرتی است و ممکن است در مواجهه با دادههای نویزی عملکرد ضعیفی داشته باشد.
با این حال، با توجه به سادگی و قابلیت انعطافپذیری الگوریتم KNN، این روش همچنان یکی از ابزارهای مورد استفاده در حوزه یادگیری ماشین محسوب میشود.
به عنوان یک روش غیرپارامتری، KNN میتواند برای مسائل مختلفی از جمله دستهبندی و پیشبینی استفاده شود و با توجه به مزایا و معایب آن، انتخاب مناسبی برای بسیاری از مسائل میباشد.
مقایسه الگوریتم K-Nearest Neighbor با الگوریتمهای دیگر در یادگیری ماشین
در این الگوریتم، برای پیشبینی برچسب یک نمونه جدید، از برچسبهای نمونههای مشابهی که در مجموعه داده وجود دارند، استفاده میشود.
یکی از ویژگیهای الگوریتم KNN این است که بدون نیاز به فرضیات خاص، میتواند برای مسائل مختلف مورد استفاده قرار گیرد.
اما این الگوریتم دارای محدودیتهایی نیز است.
به عنوان مثال، این الگوریتم برای مجموعه دادههای بزرگ و با ابعاد بالا، عملکرد بهتری نسبت به الگوریتمهای دیگر ندارد.
برای مقایسه عملکرد الگوریتم KNN با الگوریتمهای دیگر، میتوان به الگوریتمهای Support Vector Machine (SVM) و Decision Tree اشاره کرد.
SVM یک الگوریتم کلاسیک در یادگیری ماشین است که بر اساس یافتن یک صفحه جداکننده برای دادهها عمل میکند.
از طرف دیگر، Decision Tree یک الگوریتم ساختاری است که با استفاده از یک درخت تصمیم، دادهها را به دستههای مختلف تقسیم میکند.
با توجه به مقایسهای که انجام شده، مشخص است که هر یک از این الگوریتمها ویژگیها و محدودیتهای خود را دارند.
برای انتخاب الگوریتم مناسب برای یک مسئله خاص، باید به ویژگیهای داده، اندازه مجموعه داده و نوع مسئله توجه کرد.
در نهایت، انتخاب الگوریتم مناسب برای یادگیری ماشین بستگی به شرایط خاص هر مسئله دارد.
اما با درک عمیقتر از ویژگیها و عملکرد هر الگوریتم، میتوان بهترین تصمیم را برای حل مسئله مورد نظر اتخاذ کرد.

کاربردهای مختلف الگوریتم K-Nearest Neighbor در صنایع مختلف
این الگوریتم بر اساس اصل همسایگی عمل میکند و برای پیشبینی مقادیر جدید از دادههای موجود استفاده میشود.
یکی از کاربردهای اصلی الگوریتم K-Nearest Neighbor در حوزه پزشکی است.
این الگوریتم میتواند به پزشکان کمک کند تا بر اساس دادههای بیماران قبلی، تشخیص دقیقتری برای بیماران جدید بگذارند.
به عنوان مثال، با استفاده از این الگوریتم میتوان پیشبینی کرد که یک بیمار با ویژگیهای خاص به چه احتمالی به یک بیماری خاص مبتلا خواهد شد.
در حوزه بازاریابی نیز الگوریتم K-Nearest Neighbor مورد استفاده قرار میگیرد.
این الگوریتم میتواند به کسب و کارها کمک کند تا با تحلیل دادههای مشتریان، بهترین استراتژیها برای جذب مشتریان جدید را پیدا کنند.
به عنوان مثال، با استفاده از این الگوریتم میتوان مشتریان با ویژگیهای مشابه را گروهبندی کرد و به آنها پیشنهادات مشابه ارائه داد.
در علوم زمین نیز الگوریتم K-Nearest Neighbor استفاده میشود.
این الگوریتم میتواند به محققان کمک کند تا الگوهای مختلف در دادههای جغرافیایی را شناسایی کنند و پیشبینیهای دقیقتری برای آینده ارائه دهند.
به عنوان مثال، با استفاده از این الگوریتم میتوان الگوهای آب و هوایی را تحلیل کرد و به پیشبینیهای دقیقتری درباره آب و هوای آینده دست یافت.
به طور کلی، الگوریتم K-Nearest Neighbor یک ابزار قدرتمند در حوزه یادگیری ماشین است که در صنایع مختلف مورد استفاده قرار میگیرد و میتواند به تحلیل دادهها، پیشبینیهای دقیقتر و تصمیمگیریهای بهتر کمک کند.
این الگوریتم با توجه به اصل همسایگی، به صورت موثری با دادهها برخورد میکند و به تحلیل دقیقتر دادهها کمک میکند.
روشهای بهبود عملکرد الگوریتم K-Nearest Neighbor
این الگوریتم بر اساس فاصله دادهها از یکدیگر عمل میکند و برای هر نقطه از دادههای آموزشی، K نقطه مشابه آن را پیدا میکند و بر اساس اکثریت دستهبندی آنها، نقطه مورد نظر را دستهبندی میکند.
اما این الگوریتم نیز مشکلات و محدودیتهای خود را دارد که میتوان با استفاده از روشهای بهبود عملکرد آن، این مشکلات را حل کرد.
یکی از روشهای بهبود عملکرد الگوریتم K-Nearest Neighbor، انتخاب بهترین مقدار K است.
انتخاب مقدار مناسب برای K میتواند تأثیر زیادی بر دقت و عملکرد الگوریتم داشته باشد.
برای این منظور، میتوان از روشهای مختلفی مانند محاسبه خطا بر روی دادههای آموزشی و اعتبارسنجی متقابل استفاده کرد.
روش دیگری که میتوان برای بهبود عملکرد الگوریتم K-Nearest Neighbor استفاده کرد، استفاده از وزندهی به دادهها است.
در این روش، به هر نقطه از دادههای آموزشی وزنی نسبت داده میشود که بر اساس آن، نقطههایی که فاصله کمتری با نقطه مورد نظر دارند، وزن بیشتری در محاسبات دارند.
همچنین، استفاده از تکنیکهای پیشپردازش دادهها نیز میتواند به بهبود عملکرد الگوریتم K-Nearest Neighbor کمک کند.
این تکنیکها شامل نرمالسازی دادهها، حذف دادههای پرت، و حذف ویژگیهای غیرضروری میشود.
با استفاده از این روشها و تکنیکها، میتوان عملکرد الگوریتم K-Nearest Neighbor را بهبود داد و دقت دستهبندی دادهها را افزایش داد.
این الگوریتم با اعمال بهینهسازیهای لازم، میتواند یکی از بهترین الگوریتمهای دستهبندی دادهها باشد.
منبع » آکادمی اشکان مستوفی




